

How do we make diffusion models more controllable and interpretable?
Text-to-image diffusion models can create infinite diverse images from a single prompt, but we don't really understand how they organize their creative knowledge. Until now, users had to discover interesting creative variations through trial and error - tweaking text descriptions, combining different styles, or referencing other images. This process relies heavily on user creativity rather than understanding what the model actually knows about different concepts.
We introduce SliderSpace - a way to unlock the creative potential of diffusion models. Instead of requiring users to find creative directions, SliderSpace automatically discovers them from the model's knowledge. Given a concept prompt like "toy", SliderSpace identifies the key visual variations the model knows about it and turns them into simple sliders. No need to tell it what to look for - SliderSpace finds these creative controls on its own.

Why discover directions automatically?
Recent diffusion models learn from billions of text-images pairs and gain rich knowledge about different visual concepts. Having users manually specify control directions - like "make it more red" or "make it more realistic" - only scratches the surface of what these models understand. It's similar to trying to organize a massive library by only looking at book covers - you'll miss many important categories and connections that exist within.
By letting the model reveal its own understanding, SliderSpace uncovers creative possibilities that might not be obvious to humans. For example, when exploring the concept "monster", SliderSpace discovers not just obvious controls like size and color, but also nuanced variations in creature anatomy, texture patterns, and environmental elements that we might not think to specify manually. This automated discovery helps us better utilize the full creative potential that exists within these AI models.
How does SliderSpace discover meaningful directions?
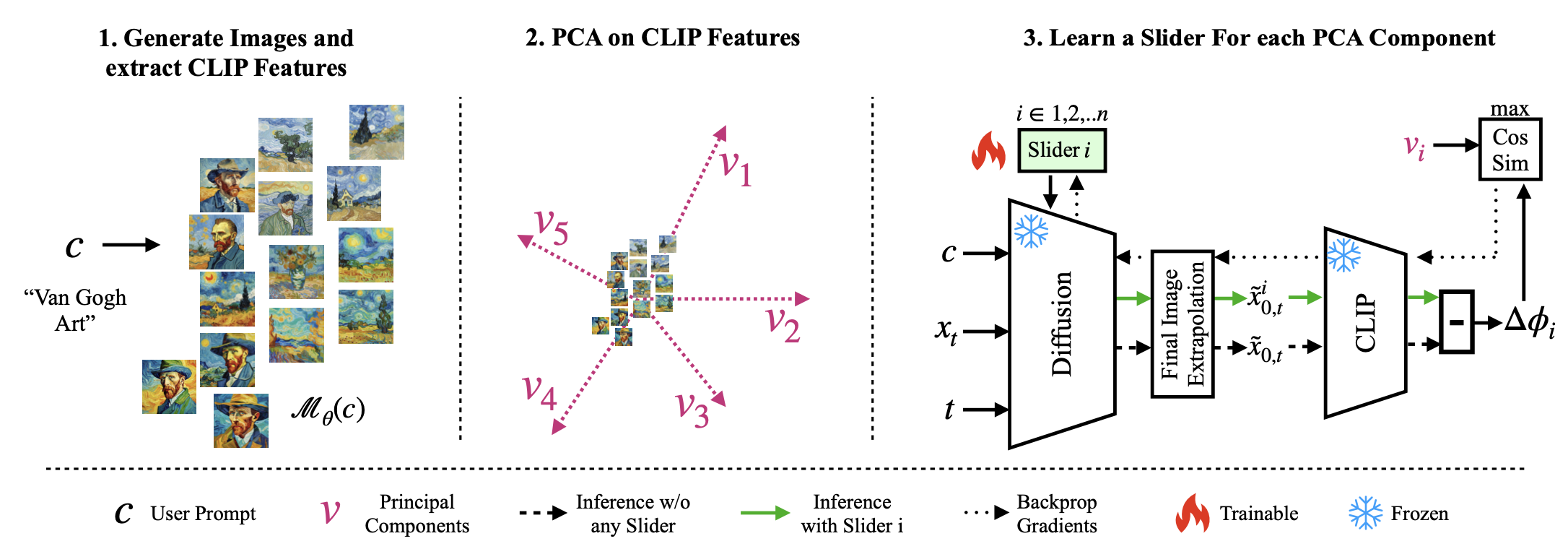
For a given prompt, diffusion model can generate an endless variety of images. SliderSpace uses this capability to understand how the diffusion model thinks about that prompt. Think of it as studying hundreds of drawings to understand an artist's different interpretations of the same concept.
To capture this knowledge systematically, SliderSpace uses low rank adapters called sliders. However, finding meaningful variations isn't straightforward - we need a way to identify changes that make sense to humans. This is why SliderSpace uses CLIP, an contrastive model that understands images in ways that is explainable through natural language. By analyzing diffusion models' variations through CLIP's understanding, SliderSpace ensures the discovered controls are meaningful and intuitive. SliderSpace decomposes a concept based on 3 key desiderata:
- Unsupervised Discovery: Directions emerge naturally from the model's learned manifold without imposing predefined attributes
- Semantic Orthogonality: Each discovered direction represents a distinct semantic aspect, preventing redundant controls
- Distribution Consistency:Transformations by a discovered direction remain consistent across different random seeds and prompt variations
To be precise, SliderSpace first generates a few variations of images from the user defined prompt. It then captures the CLIP features for each individual image and decomposes the directions through PCA. These PCA directions capture the prinicple semantic directions of variations in the diffusion model's knowledge. Once the directions are discovered, SliderSpace trains a slider to capture each individual direction. This way, a slider would steer the diffusion model towards a semantic direction (e.g. "lego" direction for the concept "toy").
How is SliderSpace useful?
SliderSpace can be used for decomposing knowledge of diffusion model about a concept. These directions can be used not only for controlling the diffusion model's outputs but also as an interpretability tool to explore the knowledge of a concept. For example, users can explore the concept of art in a pretrained diffusion model or explore the concept of "diversity".
Concept Decomposition
Given a concept like "monster", SliderSpace reveals fascinating insights into how the model think. The discovered controls went far beyond basic attributes, uncovering dimensions like creature anatomy, environmental context, and artistic interpretation. Our measurements showed that images created using these SliderSpace controls were 40% more diverse than base model's generations.




Exploring Artistic Knowledge of the Model
Instead of relying on artist names or style descriptions, SliderSpace automatically can map out how diffusion models understand artistic style. By analyzing "artwork in the style of a famous artist", it discovered distinct artistic directions. These automatically discovered controls proved remarkably effective - they closely match the diversity of manually curated artist lists that took months to compile. In fact, when compared against a dataset of 4,388 artist styles, SliderSpace achieved comparable diversity with far fewer controls.
Our user studies validated this: 72% of participants found SliderSpace's style controls more useful than traditional methods.

Improving Diversity of a Model
We discovered SliderSpace for generic prompts from COCO-30K on SDXL-DMD, a fast 4-step distilled model that typically produces less diverse images than its base SDXL version. SliderSpace improved the diversity score (FID) from 15.52 to 12.12 (lower is better), nearly matching the original model's score of 11.72. This means users can enjoy both fast generation and rich variety. Importantly, these improvements worked across different diffusion architectures, including SDXL, SDXL-Turbo, and FLUX Schnell, showing the method's broad applicability.

How to cite
The paper can be cited as follows.
bibliography
Rohit Gandikota, Zongze Wu, Richard Zhang, David Bau, Eli Shechtman, Nick Kolkin. "SliderSpace: Decomposing the Visual Capabilities of Diffusion Models." In Proceedings of the IEEE/CVF international conference on computer vision (2025).
bibtex
@inproceedings{gandikota2025sliderspace,
title={SliderSpace: Decomposing the Visual Capabilities of Diffusion Models},
author={Gandikota, Rohit and Wu, Zongze and Zhang, Richard and Bau, David and Shechtman, Eli and Kolkin, Nick},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
year={2025},
note={arXiv:2502.01639}
}